
Person of the Day and Tomorrow
Published in Witte de With Review and WdW Review: Arts, Culture and Journalism in Revolt, Vol. 1 (2013-2016)
Julia Weist and Stefan Keidel, 2016
We decided to create a mathematical model that would allow us to analyze the popularity of imagined futures, a tool that could use narrative to predict how strongly an audience might want to ‘live’ various articulated realities. We wanted to write a movie synopsis for a hypothetical film about the future of the internet, based on our own trend forecasting, and determine if it would be a success at the box office. Could such a project use our relationship to film to measure widely held anxieties and aspirations about technology?
Algorithmic analysis of preproduction cinema is not a new concept: Hollywood has embraced various predictive frameworks to mitigate the huge risk of big-budget pictures. There are algorithms that process screenplays and assess advertising strategies, word-of-mouth outcomes, and audience ratings. There are models that can be used for casting and to evaluate the return on investment for celebrity salaries, and human-centered frameworks that use mathematical market testing.
What there is less of, perhaps because it is a less exact science, is concept prediction. Evaluating a film based solely on its tombstone metadata—plot overview, tagline, keywords, genre—builds in too many assumptions to be truly useful for investment analysis. As a framework it excludes many powerful factors, including but not limited to: budget, built-in audience, franchising, marketing reach, visual quality, and spectacle. There is still value, though, in thinking of the blockbuster status a metaphor for broad interest and appeal. If you strip away any notion of quality, scale, and existing audience, what box-office hits have in common is a high-interest concept. Even films adapted from books and comics follow this logic. In fact, with these films popularity begins with concept. For these reasons, and because of our interest in evaluating possible internet futures, we put our focus on plot when we built our model.
The toolset was raw metadata, provided by IMDB, but the first step, before we built a database, adjusted for inflation, and corrected for outliers, was to write a plot. Our vision for the future of the internet was dark, but campy. The synopsis was:
In 2020, XYZ Corporation is the global leader in internet search and Lucy McGovern is the powerful executive behind the company’s experimental advertising division. It has been a year since the ubiquity of ad-blocking software nearly bankrupted the company and McGovern’s team is under intense pressure to deliver new revenue streams. When XYZ launches “Person of the Day”—or “POD”—a feature that profiles one randomly selected user on the home screen of 5 billion daily web searches, McGovern realizes they have hit internet gold and it is fully compliant with the company’s complex terms of use. Content providers line up to bid millions for exclusive information about upcoming PODs, locking out competitors and ensuring never-before-seen subscription numbers. But McGovern soon realizes there is a cost to this new funding model, and it is the lives of each Person of the Day. The spotlight of the internet hive mind is swift and unforgiving and most PODs face devastating public shame, often leading to suicide. Many call POD a new and needed form of justice, where only those with nothing to hide can survive being featured. But others, the Resistance, see only a dark and dangerous future and set off to find a way to bring advertising back to the internet.
The framework we built is filled with assumptions. The biggest is also the most basic: we presume that there is a relationship between ticket sales and the characteristics of a film. Our theory was that individual components, taken alone and together, make an impact on the earning potential of a movie. Certain aspects of this premise are most certainly true. Genre is a strong indicator of total take. Adventure and animation absolutely dominate ($127,772,892 and $125,248,753 mean box-office takes, respectively), and fantasy and sci-fi are not far behind. Good news for our film. Comparatively, romance ($32,953,850) and comedy ($38,440,514) are not all that powerful as blockbuster genres. Keywords tell a similar story. If you are given a choice between bare breasts and a hologram… choose the hologram:
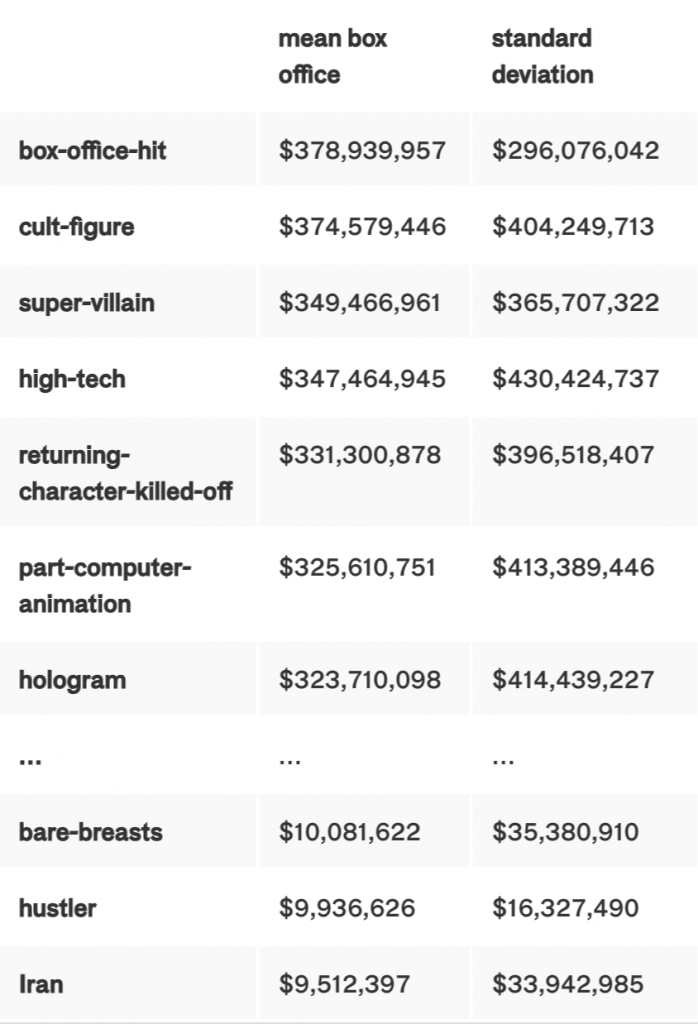
Technology is a powerful keyword: “high-tech” is number four overall by mean.
So how did we evaluate our future for the future of the Internet? We built a support vector machine that was engineered and subsequently trained to predict the likelihood of the key term “box-office hit.” For the uninitiated among us, this is a math machine, not a real one.
Each word in the film concept synopsis was assigned a weight, one that either positively or negatively impacted the outcome for success. These weights are based on past performance of plots that contain the corresponding word. Here is a simplified version of how we got there: if xn is the list of words in the N-th plot summary and yn is the known outcome from the IMDB data (1 or 0, success or not), we are looking to minimize training error plus complexity term 1:
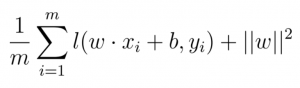
subject to
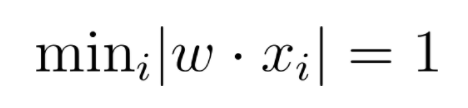
When the problem is solved, W is a list of weights for all words used in past plot summaries. We can then use it to predict if our summary would be a box-office hit or not. The model also used tf-idf, or term frequency-inverse document frequency, which prevented the disproportionate weighting of commonly used words like “the” or “and.” The model was adapted from a SMS spam detection framework.
Despite the imprecise nature of our narrative-financial construct in general, the model we built has a 94 percent precision rate for non-blockbusters and a 90 percent precision rate for blockbusters, a metric we were able to determine through repeated training and cross validation within the IMDB data set. Overall, our classifier determined that our plot was very much not a blockbuster. To get a sense of how close we were, we also had the support vector machine train a posterior probability model, a function which, for a given piece of new data and each possible outcome (“box-office hit” or not, 1 or 0) gave us a percentage that approximates the chance the data being in the corresponding class. Our plot only had a 20 percent chance of being a hit.
So which words in the internet future synopsis were helping and which were hurting the likelihood for success? Our most successful terms had to do with power, enforcement, and business: leading (+0.82), leader (+0.71), global (+0.50), billion (+0.37), justice (+0.32), corporation (+0.30), and compliant (+0.21). Among the least successful were terms related to the mundane aspects of technology use—“low-tech” words associated with daily tasks and behaviors: search (-0.77), user (-0.40), web (-0.34), profile (-0.28). This is in sharp contrast to the proven success of the “high-tech” keyword in general. Advertising was also a losing concept, with negative to neutral impact across the associated words. (Mouse over the visualization below to explore:)
In addition to the matrix for our specific synopsis, we generated an overall analysis that revealed the highest and lowest weighted words from across all plots in the dataset. Using the positive and negative trends visible in the matrix, we optimized the concept by modeling new ideas around high-impact words. Overall we sought to associate technology more with complexity and mystery, and less with knowable and scalable features. We also increased the imbalance in power, as that was the most successful aspect of our first concept.
In 2020, XYZ Corporation is the global leader in internet communication and Lucy McGovern is the powerful figurehead behind the company’s board. As leader of the California mega-company, McGovern has pursued exceedingly radical approaches and has enjoyed gigantic profit margins. When XYZ secretly summons leaders of industry, politics, and entertainment to San Francisco, buzz builds quietly that the corporation is developing a technology illuminati. To those in attendance McGovern reveals “Person of the Day,” a trial project in which one daily internet user was subjected to subtle infrastructure manipulations in XYZ products, designed to instill and foster unconscious bias. Over the course of a year, XYZ was able to alter the buying, voting, and viewing habits of each POD, toward a manufactured—and legally compliant—outcome. The members of the assembled partnership clamber to bid millions for access to the new tools, but others, the Resistance, see a dark cost to humanity. As they struggle to assemble and leak information, they find themselves faced with a life-or-death struggle for survival at the hands of those who want to keep “Person of the Day” a well-kept secret.
The optimized plot was markedly more successful. Whereas the first synopsis received a 20 percent probability from the model, the second came in at 93 percent. In our optimized plot we sought to exaggerate mystery and power, but the new synopsis also felt more categorically futuristic (perhaps because we deliberately reduced references to pedantic features of the known web). In mathematical terms, this was just a hunch, but it was technically possible to measure contemporaneity, so we built a small offshoot from our model.
We indexed the earliest film for which each synopsis word was used within the IMDB dataset. Then, we averaged these first occurrences (by the film’s production year), to determine which plot contained newer words, at least in terms of IMDB usage. Our theory turned out to be sound: the text of the second plot was on average about four years younger than the first.
Not only had we made our future more successful but, as it turned out, we had also made it more futuristic.